
twitter API v2を使って、任意のキーワードのツイート数を集計する
はじめに
アイディア出しや、周辺調査にツイッターのツイートを集計できたら便利だよね、というモチベーションから今回の実装を行なっています。
TwitterのAPIはとても便利なものではあるのですが、一度のリエストで取得できるツイート数が100件であり、送信できるリクエスト数にも制限があります。
ここらの制限について無量枠でいかに戦うかということを紹介します。ちなみに課金すれば全て解決します。笑
Twitter Developerへの登録
2020年8月12日にサードパーティ向けにTwitter API v2がリリースされました。 前回のAPIから手順が少し変更していたりします。
登録や、キーの取得はこちらのSIOS Tech Labさんの記事が参考になります。自分はこのページを見ながら作成しました。
python で Twitter API を呼び出す
ツイートの取得は以下のコードで行えます。Your Bearer Tokenの部分は自身で取得したトークンを貼り付けてください。
import urllib3
import json
def get_tweet_by_text(http, key, search_feild):
url = 'https://api.twitter.com/2/tweets/search/recent'
req = http.request('GET', url, headers= {'Authorization': 'Bearer ' + key}, fields = search_feild)
result = json.loads(req.data)
return resulthttp = urllib3.PoolManager()
KEY = '<<Your Bearer Token>>'
params = {'query' : '鳥',
'max_results' : 20
}
get_tweet_by_text(http, KEY, params)これを実行すると以下のような結果が出力されます。鳥を含む一番新しいツイートを20件取得できました。paramsの詳細は以下のドキュメントに記載があります。start_timeやend_timeを設定すれば期間を限定することも可能です。
https://developer.twitter.com/en/docs/twitter-api/pagination
{'data': [{'id': '1504044081659641863',
'text': 'RT @MAFF_JAPAN: 鳥インフルエンザは、A型インフルエンザウイルスが引き起こす「鳥の病気」です(人の病気ではありません)。\n渡り鳥が飛来する11月~3月頃に多く発生します。\n養鶏農家の皆様は衛生管理の徹底に努めていらっしゃいますので、農場には不用意に近づかないように…'},
省略
{'id': '1504043984905457668', 'text': '@kizoku_dayo 鳥貴族'}],
'meta': {'newest_id': '1504044081659641863',
'next_token': 'b26v89c19zqg8o3fpyqmx8pk1fiq860my6ma5y4smf0xp',
'oldest_id': '1504043984905457668',
'result_count': 20}}APIの制限
取得制限
一度のリクエストで取得できるツイート数は100件までです。それを超える場合はループ処理を使うことで取得できます。最大取得数の100件を超えてまだツイート情報がある場合は、レスポンス時の辞書型データに[next_token]が返ってくるので、次のクエリにパラメータとして与えることで続くツイートを取得できます。
has_next = True
while has_next:
result = get_tweet_by_text(http, KEY, params)
print(result)
# 取得制限対策
if not 'meta' in result:
break
# flag
has_next = 'next_token' in result['meta']
if has_next:
params['next_token'] = result['meta']['next_token']これで取得制限を超えてツイートを収集することができます。
リクエスト数制限
ここまで来ると次に問題になるのはリクエスト数の制限です。ニッチな単語であれば問題ありませんが、猫や鳥など、メジャーな単語を含むツイートを収集しようと思うと制限に引っかかってしまいます。そこで、取得する時間を限定しました。毎時5分間ツイートを集計して単純に12倍してあげることで、擬似的に一時間分のツイートを集めたことにしよう、という方針です。呟かれている文章自体に価値を見出したい場合はこの手法は適さないかも知れません。
paramsに設定する時間を更新していくことで、適当な時間ごとにツイートを取得します。
def set_params(field, max, start_time, end_time):
params = {'query' : field,
'max_results' : max,
'start_time': start_time.isoformat(),
'end_time': end_time.isoformat()
}
return params
from datetime import date, time, datetime, timezone, timedelta
import pandas as pd
# 開始時刻と終了時刻の設定
today = date.today()
time = time(0)
# 検索ワード
field = '焼き鳥'
# 取得したデータをpandasで扱うため
concat_df = pd.DataFrame()
# 2時間おきに5分間だけ集計する
hour = 8
minutes_per_hour = 5
for i in range(50):
has_next = True
end_time = datetime.combine(today, time, tzinfo=timezone(timedelta(hours=9)))
end_time = end_time - timedelta(hours=hour*i)
start_time = end_time - timedelta(minutes=minutes_per_hour)
# params 設定
params = set_params(field, 100, start_time, end_time)
while has_next:
result = get_tweet_by_text(http, KEY, params)
# 取得制限対策
if not 'meta' in result:
break
# flag
has_next = 'next_token' in result['meta']
if 'data' in result:
df = pd.DataFrame(result['data'])
df['timestamp'] = end_time
concat_df = pd.concat([concat_df, df], axis=0)
if has_next:
params['next_token'] = result['meta']['next_token']
concat_df.head()実行結果

pandasでデータを集計することができました。後はこれを可視化していきます。
ツイート日時の可視化
今回は3/10〜3/16日までの一週間分ツイートを日毎に集計しています。
df = concat_df.groupby(pd.Grouper(key="timestamp", freq="D")).count()['id']
df = pd.DataFrame(df).reset_index()
df['timestamp'] = df['timestamp'].dt.strftime('%m/%d')
df = df.set_index('timestamp')['id']
df = df * hour #概算する
df.plot(kind="bar")
単語抽出
折角ツイート全文のデータも取れているので、利用したいくなりますね。今回は単純に同時にツイートされている単語を抽出して、そのランキングを作成することにしました。ネガポジ分析なんかを使ってみても面白そうです。テキストマイニングにはMecabを利用します。
#MeCabで分割
import MeCab
m = MeCab.Tagger()
# ツイートを全て繋げて一つの文章に変換
text = concat_df['text'].values
text = ' '.join(text)
node = m.parseToNode(text)
words=[]
while node:
hinshi = node.feature.split(",")[0]
if hinshi in ["名詞", "名前",]:
split = node.feature.split(",")
if len(split) > 7:
origin = split[7]
words.append(origin)
node = node.next#単語の数カウント
import collections
c = collections.Counter(words)
pd.DataFrame(c.most_common(10)).rename({0:'word', 1:'count'}, axis=1)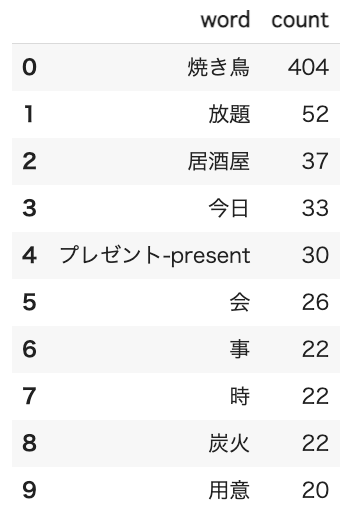
焼き鳥とよく使われる単語は放題、居酒屋などお酒と関連するツイートが多いみたいですね。放題は食べ放題からでしょうか?焼き鳥食べ放題なんて羨ましい限りです。
おわりに
Twitter API v2を利用してツイート数の可視化と、頻出単語を並べてみました。単純に適当な単語入れてみるだけでも十分遊べました。テキストマイニングの方はまだまだ遊べそうといった感じです。
これを利用したWebアプリを作成しました!よければこちらも覗いてみてください。








