![[python] LSTMで株価予測](https://is-ai.jp/wp-content/uploads/2022/09/92e2654e0c2e81bd4f7640a2be90acd5.png)
はじめに
深層学習などを勉強したり、触っていたりすると、結構な人が株価や為替などに利用できないかと考えるものですよね。自分もそれに漏れず、自分で作ってみたいと常々思っていました。
そして実際に作成し、四ヶ月間にわたり深層学習モデルを使って株価を予測して実際に売買を行ういうことをやっていました。(以下の記事です!)
![[python] LSTMで株価予測](https://is-ai.jp/wp-content/uploads/2022/04/22607921.jpg)
この記事ではその内容を共有しようと思います。
最初の一ヶ月間はかなり勝つことができたのですが、それ以降負け続けたことに加え、取引を完全自動化させることが難しいということで、一旦このプロジェクト自体をクローズすることにしました。
最終的に負けてクローズしたモデルではありますが、参考にできる部分はあると思うのでこうして記事に残そうと思いました。
構成
先ずは、自分が構築した全体像から紹介していこうと思います。
かなりザックリですが全体像です。
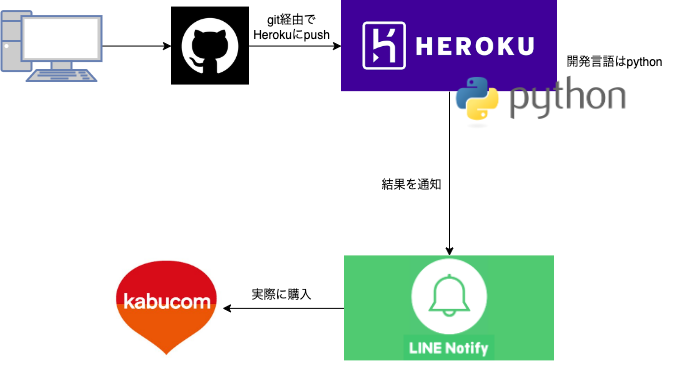
図を見るとわかりますが、簡単な構成になっています。
Herokuサーバを利用して、日毎に翌日の予測結果をline通知として返すような構成になっています。使用言語はpythonを使っています。
コードの管理はgitで行なっており、herokuサーバにプッシュすることで更新が走るようになっています。
Line通知に飛んできた情報をもとにカブコム証券で指定の銘柄を購入&売却していました。
この購入と売却の部分は手動で行なっており、本当はここを自動化したかったのですが、カブコム証券の個人アカウントではAPIの制限上難しそうだったので断念しました。
実装
実装は以下の3パーツに分かれています。
・前日までの株価データ収集
・LSTMでモデルを構築(pytorch)
・line notifyで通知する
株価の収集にはyahooのAPIを利用しています。yahoo_finance_api2で検索してもらえると他の方々がまとめてくれている記事がたくさんヒットすると思います。
こちらを利用して、株式情報を収集しました。
APIを叩いて、株式のデータを全てpandasのdataframe形式に詰め込んで返しています。
from yahoo_finance_api2 import share
from yahoo_finance_api2.exceptions import YahooFinanceError
def get_stock_info(code, N_day=180):
my_share = share.Share(f'{code}.T')
symbol_data = None
try:
symbol_data = my_share.get_historical(
share.PERIOD_TYPE_DAY, N_day,
share.FREQUENCY_TYPE_DAY, 1)
except YahooFinanceError as e:
sys.exit(1)
df = pd.DataFrame(symbol_data)
df["datetime"] = pd.to_datetime(df.timestamp, unit="ms")
if df.isnull().values.sum() != 0:
raise ValueError("Exception")
if len(df) != row:
raise ValueError("Exception")
# 取引量が少なければ削除(500万以下)
if df['volume'].min()*df['low'].min() < 5000000:
raise ValueError("Exception")
#日本時間へ変換
df["datetime_JST"] = df["datetime"] + datetime.timedelta(hours=9)
df = df.set_index('datetime_JST')
df = df.drop(['datetime', 'timestamp'], axis=1)
return dfモデル構成とデータセット構成は以下のように構築しました。
フレームワークにはpytorchを使用しており、上記のdataframeに対して、自作のデータベースクラスを作成しています。
class LSTMPVClassifier(nn.Module):
def __init__(self, embedding_dim, lstm_hidden_size, mlp_hidden_size, output_size, dropout):
super(LSTMPVClassifier, self).__init__()
self.lstm_hidden_size = lstm_hidden_size
self.dropout = nn.Dropout(dropout)
self.lstm = nn.LSTM(embedding_dim, self.lstm_hidden_size, batch_first=True,
num_layers=1, bidirectional=False, dropout=0.0)
self.fc1 = nn.Linear(self.lstm_hidden_size, mlp_hidden_size)
self.fc2 = nn.Linear(mlp_hidden_size, output_size)
def forward(self, x):
b_size = x.size(0) # batch size
seq_len = x.size(1) # sentence length
# init hidden and cells of LSTM
h0 = torch.zeros(1, b_size, self.lstm_hidden_size).to(device)
c0 = torch.zeros(1, b_size, self.lstm_hidden_size).to(device)
# execute LSTM
lstm_output_seq, (h_n, c_n) = self.lstm(x, (h0, c0))
out = self.dropout(self.fc1(lstm_output_seq))
out = self.fc2(out)
return out
class MyDataset(torch.utils.data.Dataset):
def __init__(self, X, y, z):
self.data = X
self.teacher = y
self.code = z
def __len__(self):
return len(self.teacher)
def __getitem__(self, idx):
out_data = self.data[idx]
out_label = self.teacher[idx]
out_code = self.code[idx]
return out_data, out_label, out_codetrain_dataset = MyDataset(X_train, y_train, z_train)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size)
val_dataset = MyDataset(X_val, y_val, z_val)
val_dataloader = DataLoader(val_dataset, batch_size=batch_size)
test_dataset = MyDataset(X_test, y_val, z_val)
test_dataloader = DataLoader(test_dataset, batch_size=1)
print("train_size, val_size",len(X_train), len(X_val))各種ハイパーパラメータ設定と実際の学習過程がこちらです。
# define network and hyperparameter for training
dropout = 0.0
lstm_hidden_size = 256
emb_dim = X.shape[2]
mlp_hidden = 64
output_size = 1
net = LSTMPVClassifier(emb_dim, lstm_hidden_size, mlp_hidden,
output_size, dropout)
net = net.to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, net.parameters()))
# training
num_epochs = 10
train_loss_list = []
val_loss_list = []
for epoch in range(num_epochs):
train_loss = 0.0
val_loss = 0.0
train_acc = 0.0
val_acc = 0.0
train_y = []
train_predicted = []
val_y = []
val_predicted = []
#train
net.train()
for i, batch in enumerate(train_dataloader):
input, labels, _ = batch
input = input.to(device)
labels = labels.to(device)
f_labels = labels.float()
optimizer.zero_grad()
output = net(input)
outputs = output[:, -1].squeeze()
if f_labels.size()[0] == 1:
continue
loss = criterion(outputs, f_labels)
train_loss += loss.item()
loss.backward()
optimizer.step()
avg_train_loss = train_loss / len(train_dataloader.dataset)
#val
net.eval()
with torch.no_grad():
for batch in val_dataloader:
input, labels, _ = batch
input = input.to(device)
labels = labels.to(device)
f_labels = labels.float()
outputs = net(input)
outputs = outputs[:, -1].squeeze()
loss = criterion(outputs, f_labels)
val_loss += loss.item()
avg_val_loss = val_loss / len(val_dataloader.dataset)
print ('Epoch [{}/{}], Loss: {loss:.4f}, val_loss: {val_loss:.4f}'
.format(epoch+1, num_epochs, i+1, loss=avg_train_loss, val_loss=avg_val_loss,))最後に結果をLineで通知しています。
def send_line_notify(notification_message):
line_notify_token = ‘YOUR’TOKEN’
line_notify_api = 'https://notify-api.line.me/api/notify'
headers = {'Authorization': f'Bearer {line_notify_token}'}
data = {'message': f'{notification_message}'}
requests.post(line_notify_api, headers = headers, data = data)より詳細な使い方は以下の記事でまとめています。
![[python] LSTMで株価予測](https://is-ai.jp/wp-content/uploads/2022/05/44c23b6b15d70994d766716b66bcaf1c.png)
おわりに
上記のようなコード用いで実装を行いました。トータル負けている構成なので、参考程度にとどめておいて頂けたらと思います!








