![[python]Filmarksのレビューをスクレイピングする](https://is-ai.jp/wp-content/uploads/2022/07/4858357_s.jpg)
はじめに
タイトルの通り、今回はFilmarksのレビュー結果をスクレイピングしていくという内容です。
スクレイピングするというタイトルではありますが、自分の場合はどうしても想定通りの挙動を起こせなかったので、一旦諦めました。ただ現時点でも十分利用価値のあるコードだと思うので記事にまとめます。
そういった状況を加味した上で説明していきます。
[注意]スクレイピングしたデータの使用に関しては自己責任でお願いします。
スクレイピングの違法性についてはこちらの記事でまとめているので、興味がある方は是非ご覧になってください。結構気合を入れて調査しました!!
![[python]Filmarksのレビューをスクレイピングする](https://is-ai.jp/wp-content/uploads/2022/08/email-4284157.png)
問題点
では、本題です。今回自分がぶつかった壁が大きく二つあります。
・サーバからのレスポンスが遅く、要素が取れずにエラーで停止
・タイトル検索で飛びたいタイトルページに飛べない
一つ目に関しては例外処理などを使って対処できていたのですが、問題は二つ目です。
今回自分の使い方では、
- 検索タイトルにタイトルを入力
- 一番上の候補を選択
- 飛んだ先のページでレビューを拾う
という、上記のパターンを繰り返すことでレビューを取得していました。この取得方法だと一番上の候補とタイトルが噛み合わないことがたまに発生したためデータの信頼性が下がってしまいました。
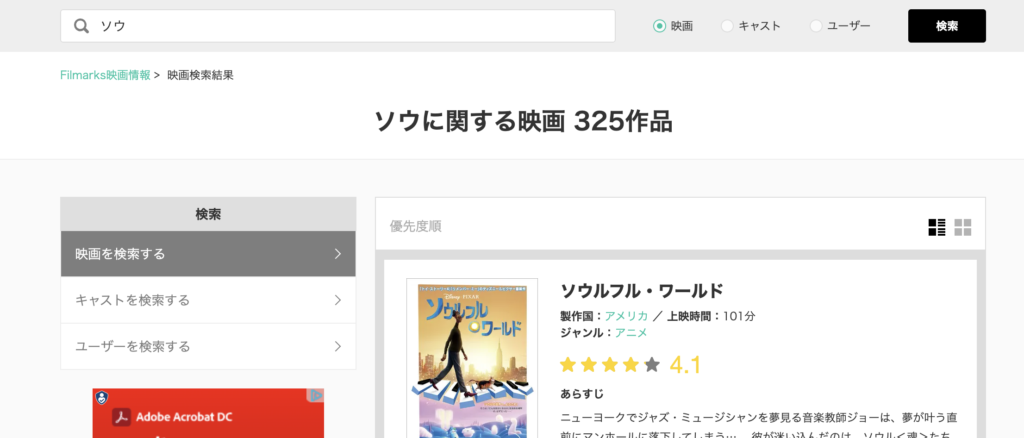
例えば、"ソウ"という映画がありますが、検索結果の一番上にくるタイトルは"ソウルフル・ワールド"という別のタイトルが最上位にきてしまいます。
こういった現象が稀に発生することが一番の問題点でした。
*追記
検索候補と入力文字のタイトルが完全一致しているかをチェックすれば実装できそうですね。。
コード
今回は作成した関数の紹介をします。
get_page_review関数にタイトルを渡してあげればレビューが取得できるようになっています。
# import & パラメータ定義
from time import sleep, time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
CONNECTION_RETRY = 10
options = Options()
options.binary_location = '/Applications/Google Chrome Beta.app/Contents/MacOS/Google Chrome Beta'
driver = webdriver.Chrome(service=Service('./chromedriver-bata'), options=options)
# タイトルを入れてそのタイトルページの映画レビューを取得
def get_page_review(film_title, i=1):
if not select_movie_item_with_retry(film_title):
exit()
else:
basepath = driver.current_url
while True:
access_url = basepath + f'?page={i}'
print(access_url)
try:
driver.get(access_url)
except:
break
sleep(0.2)
try:
reviews = driver.find_elements(by=By.CLASS_NAME, value='p-mark__review')
goods = driver.find_elements(by=By.CLASS_NAME, value='c-reactions__count')
scores = driver.find_elements(by=By.CLASS_NAME, value='c-rating__score')
except:
print('continue')
i += 1
continue
# no review
if len(reviews)==0 and len(goods)==0 and len(scores)==0:
break
for review, good, score in zip(reviews, goods, scores):
print(review.text, good.text, score.text)
i += 1
# 100ページ分取得したら終了
if i >= 100:
break
def select_movie_item_with_retry(film_title):
print(f'https://filmarks.com/search/movies?q="{film_title}"')
driver.get(f'https://filmarks.com/search/movies?q="{film_title}"')
for i in range(1, CONNECTION_RETRY + 1):
try:
driver.find_elements(by=By.CLASS_NAME, value="p-content-cassette__jacket")[0].click()
except Exception as e:
print("error:{e} retry:{i}/{max}".format(e=e, i=i, max=CONNECTION_RETRY))
sleep(1)
else:
return True
return False
get_page_review('Joker')また、今回紹介した記事ではchromeのbetaバージョンを利用しています。
使い方はこちらの記事でまとめているので、beta版を利用する場合は参考にしてみてください。
![[python]Filmarksのレビューをスクレイピングする](https://is-ai.jp/wp-content/uploads/2022/07/44c23b6b15d70994d766716b66bcaf1c.jpeg)
おわりに
今回、映画タイトルと対応するレビューデータが欲しかったのですが、断念しました。。
他にも方法などは考えられると思うので、また別の方法を試していこうと思います。
以上!!
![[python] LSTMで株価予測](https://is-ai.jp/wp-content/uploads/2022/09/92e2654e0c2e81bd4f7640a2be90acd5-150x150.png)